Introduction
What is Big Data? As a data science engineer, whenever you deal with large unstructured data sets, you need to use Big Data for effective data management. Did you know that Big Data handles complexities in traditional data processing application software? It determines the volume of data, categorizes the means and determines the type of data like images, PDF, audio, video, and more. Also, Big Data improves the processing speed and works on large data sets which could be structured or unstructured. It is actively involved in capturing data, search, data storage, data sharing, transfers, data analysis, visualization, querying, etc., It is also used in A/B testing, natural language processing, and machine learning. When it comes to visualization applications, Big Data is used in cloud computing, database, and business intelligence. Here are eight important big data technologies used in data science.
This blog covers the following topics:
- ● Apache Hadoop
- ● Apache Cassandra
- ● Apache Hive
- ● Apache Flume
- ● Apache Spark
- ● Apache Kafka
- ● Elasticsearch
- ● Mongo DB

Apache Hadoop
Did you know that Hadoop is one of the most widely used big data technologies that is used to handle data on a large scale? Hadoop file system, also known as HDFS, is equipped with state-of-the-art features like parallel processing and MapReduce framework. It is a scalable system that offers a robust solution that can handle large data types. For instance, NextBio, a privately owned software company that provides a platform for drug companies and life science researchers, uses Hadoop MapReduce and HBase to process multi-terabyte data sets off the human genome.

Apache Cassandra
As an open-source NoSQL database used for handling Big Data, Apache Cassandra is equipped to handle structured, semi-structured, and unstructured data seamlessly. It was developed by Facebook and was open-sourced in the year 2008. In 2010, it became one of the top-level Apache projects. It is popularly known for its scalability, flexibility, and reliability in handling large data sets. However, it does not support ACID transactions and is fault tolerant.

Apache Hive
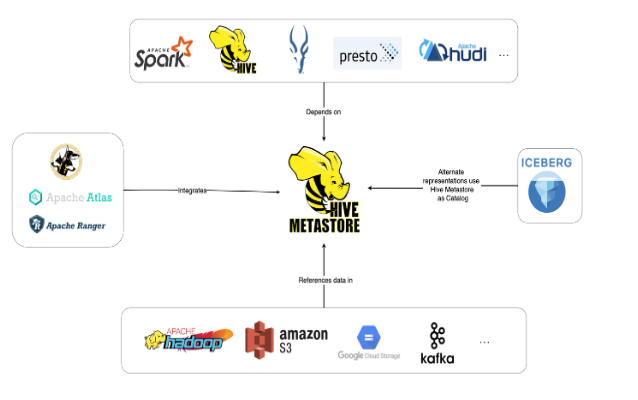
Most seasoned data science engineers prefer Apache Hive for its distributed, fault-tolerant data warehouse system that enables analytics at a large scale. Did you know that the Hive Metastore (HMS) houses a central repository of metadata that can be analyzed to make data-driven decisions, making it a critical component of data lake architectures? It is a central repository of metadata for Hive tables and partitions in a relational database. Built on top of Apache Hadoop, Hive supports storage on S3, adls, gs and more. It allows users to read, write, and manage petabytes of data using SQL. Apache Hive is a building block for data lakes that use open-source software like Presto or Apache Spark.
Apache Flume
This Big Data technology is reliable in collecting, aggregating, and moving large amounts of log data from many data sources toward a centralized data store. Apache Flume is used in Big Data environments to ingest log files, clickstreams, social media data, and other high-volume data sources.

Apache Spark
Introduced by Apache Software foundation, Apache Spark is popular for its cluster management as it is not an updated or modified version of Hadoop. It is useful in storage and processing as it implements Spark with Hadoop. With its own cluster management computation, it uses interactive queries and steam processing along with in-memory cluster computing as one of the key features. Apache Spark’s main motive is to speed up the Hadoop computational computing software process.

Apache Kafka
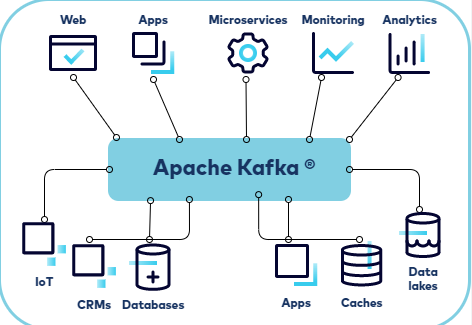
As a distributed event store and stream processing platform, Apache Kafka has a robust queue that enables users to handle a high volume of data (messages) with relative ease. It allows users to perform message computation in offline and online modes. Also, Kafka messages can be replicated within the cluster to prevent data loss. It integrates Apache Storm with Spark and is built on top of the ZooKeeper synchronization service.
MongoDB
Based on a cross-platform, MongoDB works on a concept like collection and document with document-oriented storage, which means that data will be stored in the JSON form. With features like high availability, rich queries, auto-sharding, and fast updates, it is the preferred choice for most data science engineers. It can be an index on any attribute as a fully cloud-based developer data platform. MongoDB is known for flexible document schemas, widely-supported code native data access, change-friendly design, powerful querying and analytics, simple installation, and cost-effectiveness.

Elasticsearch
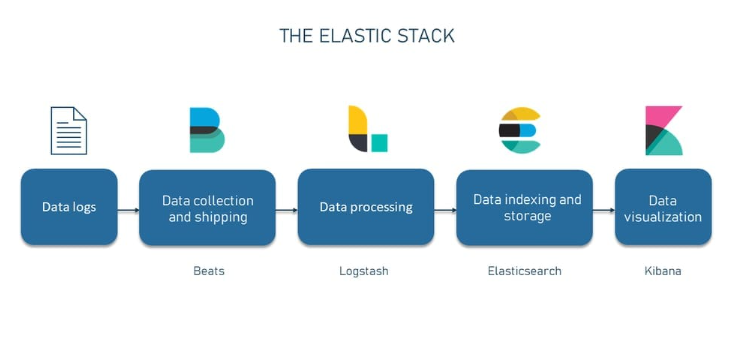
Did you know that you can get a real-time distributed system and open-source full-text search and analytics engine with Elasticsearch? It has a stellar scalability factor like scalable structured and unstructured data to petabytes. It can also be used as a replacement for MongoDB, which is based on document storage. Elasticsearch uses denormalization to improve search performance, making it the preferred choice for big organizations like Wikipedia and GitHub.
With the rise in demand for data science jobs, it is vital for professionals and freshers to have a strong grip on the latest data science technologies. You need to learn Big Data and generative AI to stay fully equipped with the latest data trends in an optimum manner. Eduinx, a leading edutech institute, offers a data science with generative AI course that can be highly useful for budding data science professionals and freshers with a basic knowledge of data science. Unlike other edutech institutes, Eduinx provides a virtual classroom environment for students to experience an in-person classroom environment and learn from experts. It focuses on the practical aspects of implementing data science concepts in real time. With a keen focus on placement and career support, Eduinx houses a team of highly skilled trainers who provide hands-on experience with capstone projects. You can reach out to Eduinx for more information on the course.
Reference links:
https://www.geeksforgeeks.org/popular-big-data-technologies/ https://www.coursera.org/articles/big-data-technologies https://www.datamation.com/big-data/big-data-technologies/