Introduction
As one of the key tools used by organizations to store and analyze data, the Hadoop ecosystem is used to assist companies in developing applications. It is the best framework to store data and is the right option for enterprise-level companies that deal with large data. As a data science engineer or a fresher who is looking to start a career in data science, having a clear understanding of the Hadoop ecosystem in Big Data is pivotal to being an established data scientist and ensuring your growth in the industry.
Due to the heavy competition in today’s corporate landscape, professionals need to constantly update themselves with the right skill set to thrive in the market. Having a good understanding of Hadoop, Big Data, and generative AI is sure to put you on a higher pedestal in the hiring market. You can also land better jobs as there is a lot of demand for data science professionals with sound knowledge of gen AI, Hadoop, and Python. Learn the Hadoop ecosystem in Big Data in this blog and strengthen your skills.
This blog covers the following topics:
- ● What is the Hadoop Ecosystem?
- ● Hadoop Ecosystem for Big Data
- ● Architecture of a Hadoop Ecosystem
- ● Tools and Frameworks Used in the Ecosystem
- ● Unique Features of the Ecosystem
What is the Hadoop Ecosystem?
As defined earlier, Hadoop is a software framework that allows users to store and process large data on a cluster of computers. It comprises two distinct parts namely, Hadoop Distributed File System (HDFS), and MapReduce. HDFS is used in large corporations as it allows users to store large data across many servers in a distributed manner. This ensures fast and easy access via requests from clients or applications. MapReduce is a unique programming model that can break down big data into smaller chunks and enables parallel processing.
The Hadoop ecosystem is a collection of tools, frameworks, and libraries that help data science engineers to build applications on top of Apache Hadoop. It is best suited to address Big Data problems as it supports massive parallelism with low latency and high throughput. The Apache Hadoop ecosystem can be used with other frameworks like Spark or Kafka for real time processing or machine learning applications.
Hadoop Ecosystem for Big Data
Did you know that Hadoop has several tools that work together to analyze and process large data? As an open-source framework, its architecture is based on widely distributed systems such as MapReduce, Pig, and Hive. MapReduce divides data inputs into small pieces, distributes them across many machines in the cluster, and combines the output from all machines into one file. This makes it the most preferred method for companies to process large data sets in one go. The output can also be run through gen AI to produce the desired data points for making the right decision.
Pig is another special tool that can write scripts in Pig Latin language, which can be used in querying large datasets stored in the Hadoop Distributed File System (HDFS). If an organization is accustomed to SQL databases, it can use Hive to store data in tables to those that are already present in SQL databases. However, it is stored as files on HDFS rather than being stored in Relational Database Management Systems (RDBMS).
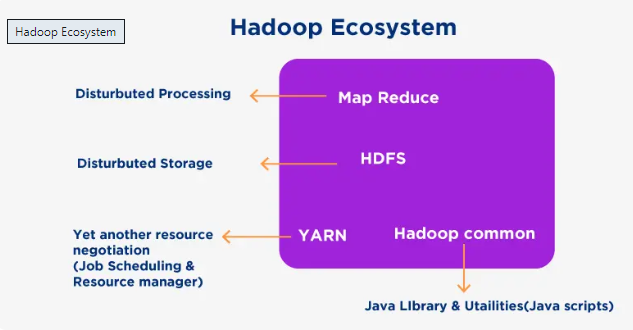
Architecture of a Hadoop Ecosystem
The Hadoop ecosystem in Big Data comprises four core components which are data storage, data processing, data access, and data management. Firstly, all raw data is stored on a local hard drive or on the cloud. In data processing, the data is analyzed and transformed into meaningful insights for further analysis. Data access is the third phase of the Hadoop ecosystem. Here, tools like Pig or Hive are used to query data sets, filter out specific rows, and sort them into certain columns or values. In the last phase of the Hadoop ecosystem architecture, all processed data is stored safely and can be recalled whenever required. This ensures optimum data management.
Tools and Frameworks Used in the Ecosystem
The Hadoop ecosystem is highly versatile in terms of incorporating tools as it supports many tools for data processing and analysis. Some tools are used in collecting data from various sources whereas others are used to store and analyze data. Here are a few important tools used in the Hadoop ecosystem.
When it comes to workflow monitoring, Oozie is an optimum management system that enables users to monitor and control workflows. This can be used to automate tasks for system administration, debugging, and data processing. If you have high-performance computing clusters and are looking for an open-source distributed monitoring system, Chukwa is the one for you. This tool collected data from Hadoop Distributed File System (HDFS), YARN, and MapReduce. It has a web interface that provides a holistic view of data collected by Chukwa agents.
Flume is an open source distributed log collection that stores log events from web servers or application servers into HDFS or other related systems. Zookeepeer is an optimum management tool that aids in managing configuration, synchronizing data, and service discovery functions of Hadoop clusters.
Did you know that there is a data warehouse system for Hadoop that allows users to query data using SQL? Hive is a system that is used to create and modify tables, and views, and grant privileges to users. As a high-level language for writing data transformation programs, Pig is used to express data analysis. These programs are compiled into MapReduce jobs that run on the Hadoop infrastructure.
MapReduce is a popular programming model that is used to process and manage large datasets. Map Phase and Reduce phase are used in MapReduce. Map Phase is used to divide input data into chunks and process it parallelly. The Reduce phase is where each group of intermediate key value pairs is passed to a reducer that processes the final output based on values in the group.
Frameworks used in the Hadoop Ecosystem
With an ever-growing collection of tools, add-ons, and libraries, the Hadoop ecosystem is used to build applications on top of the Apache Hadoop platform. Apache Avro framework allows data science engineers to input data once and read it anywhere. This means that you do not have to worry about translating data into different formats, while moving it between other systems. Thrift is an RPC framework for writing services in programming languages like C++ or Java. This can help you communicate across languages and platforms. This framework helps you write code on one platform and run it on any other platform without having to rewrite it.
Unique Features of the Ecosystem
Hadoop is a free and open-source software that enables data science professionals to process large datasets in a distributed manner. It is built with Java and can be used as commodity hardware. It can be used for large datasets which can be scaled to handle multiple terabytes of data. Linux servers, network switches, and hard drives are the components of a Hadoop ecosystem. These components can be purchased from any vendor at an affordable price. One of the unique features of Hadoop is its ability to store large unstructured data, which cannot be done on traditional SQL databases.
Are you an aspiring data science engineer looking to get updated and upskill your career? Learn data science with generative AI course at Eduinx. With a team of in-house experts who have over 10 years of industry-relevant experience, you can get the best guidance from Eduinx. They offer a virtual classroom learning experience which encompasses practical applications and capstone projects. Get in touch with Eduinx for more information on the course.
Reference links:
https://www.upgrad.com/blog/hadoop-ecosystem-components/ https://www.linkedin.com/pulse/hadoop-ecosystem-components-smriti-saini/ https://www.geeksforgeeks.org/hadoop-ecosystem/